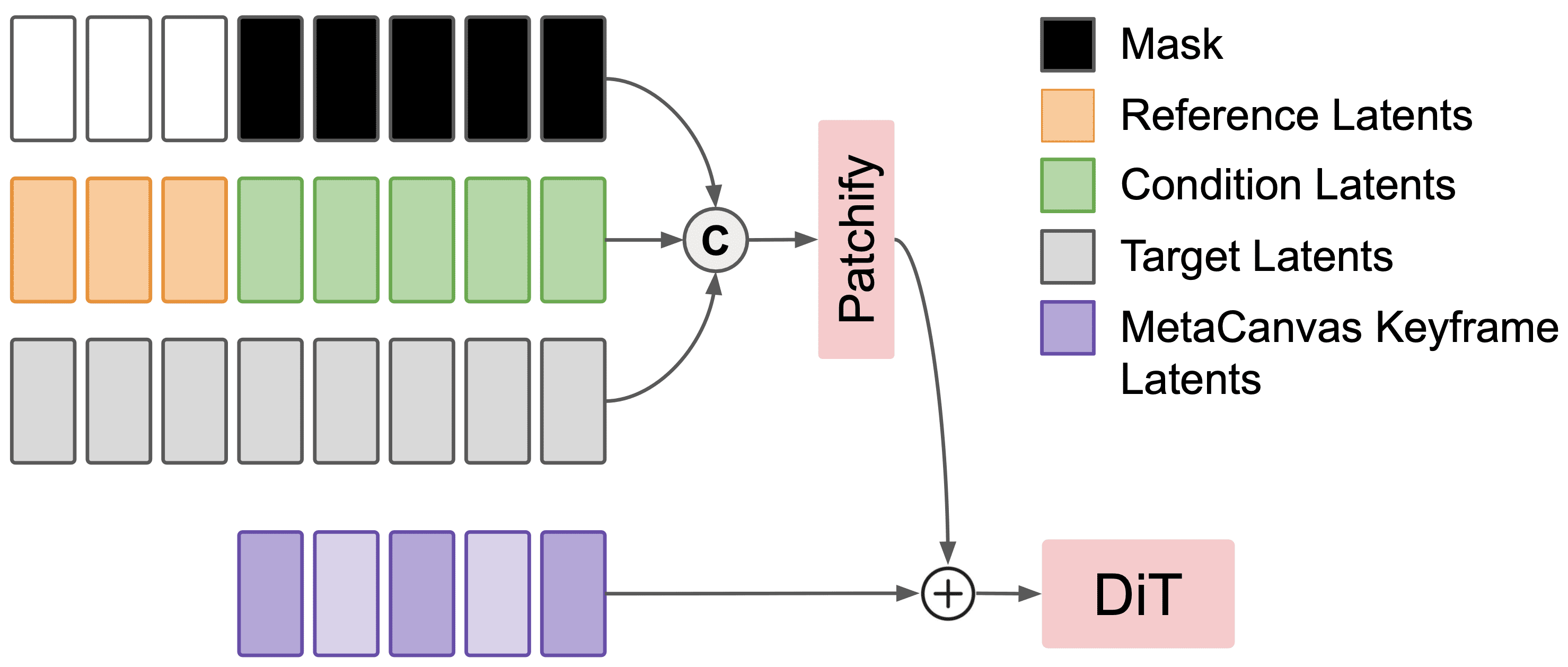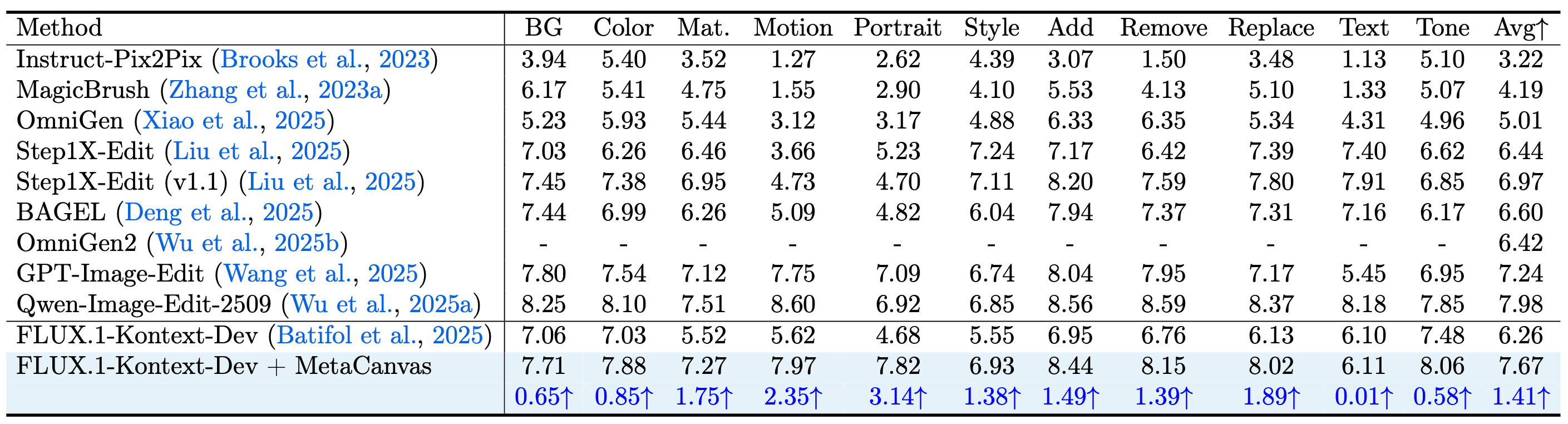
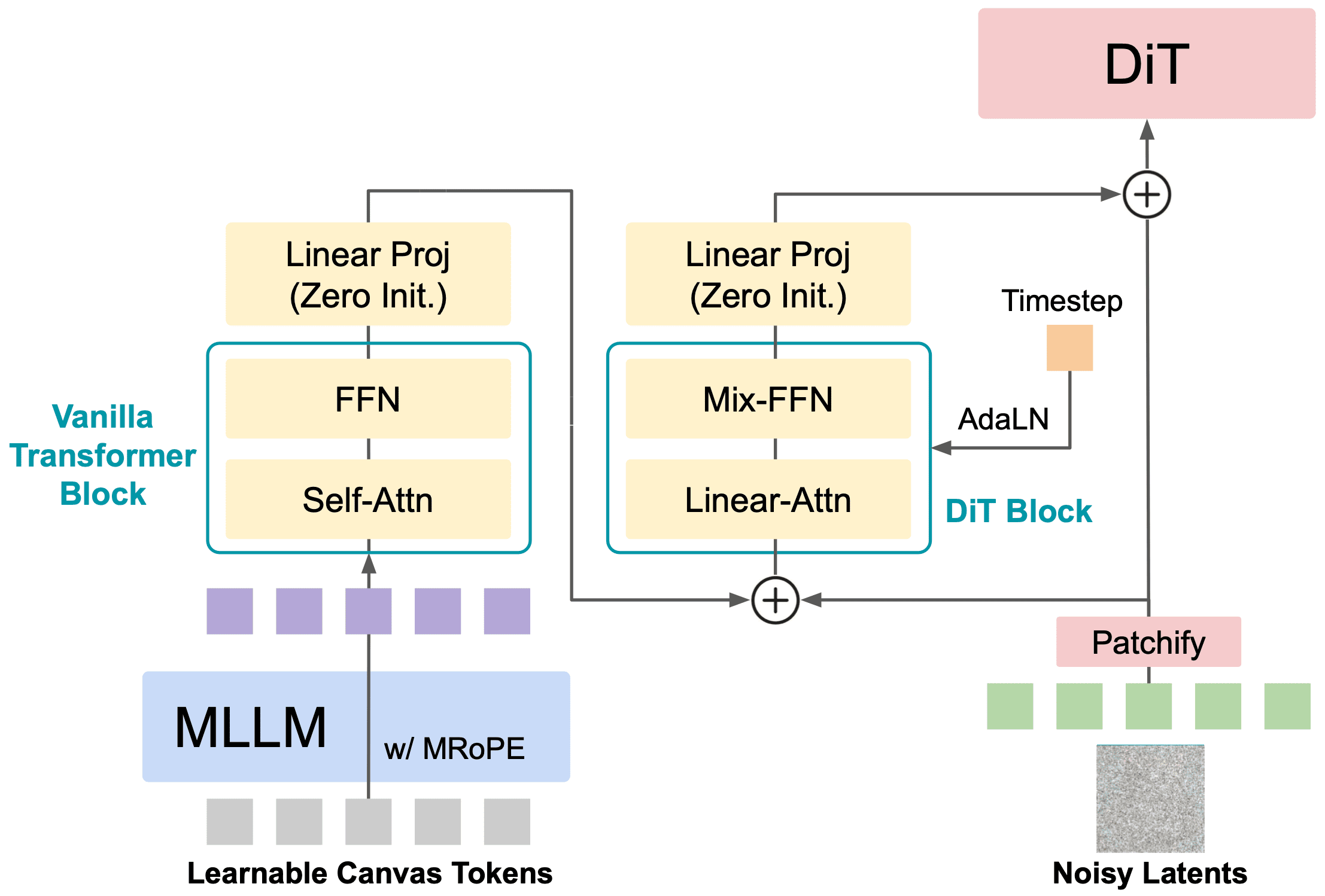
Figure 2: MetaCanvas connector design details.
Method (see more details below ↓)
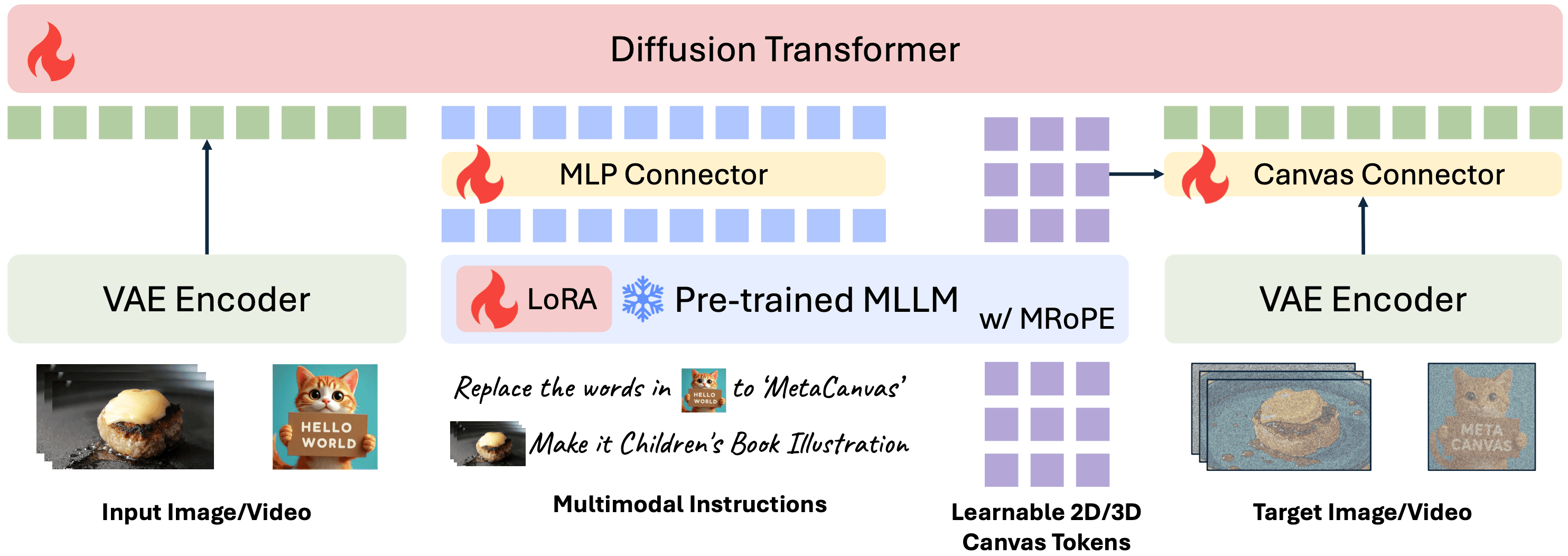
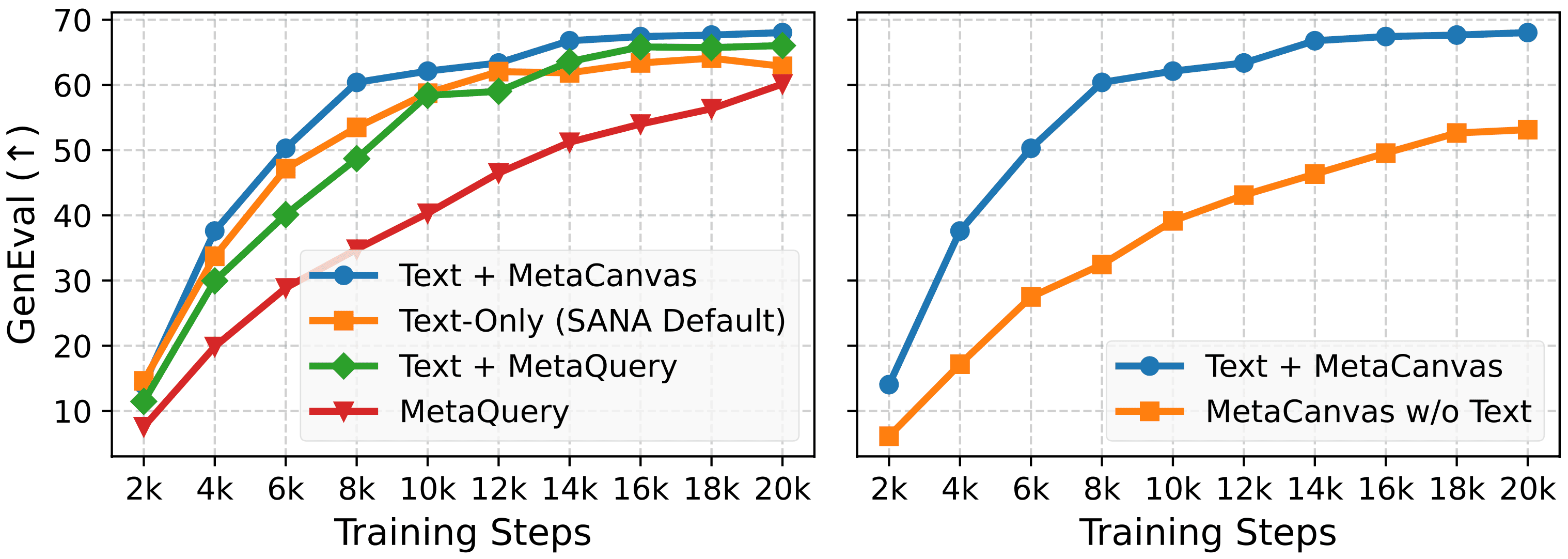
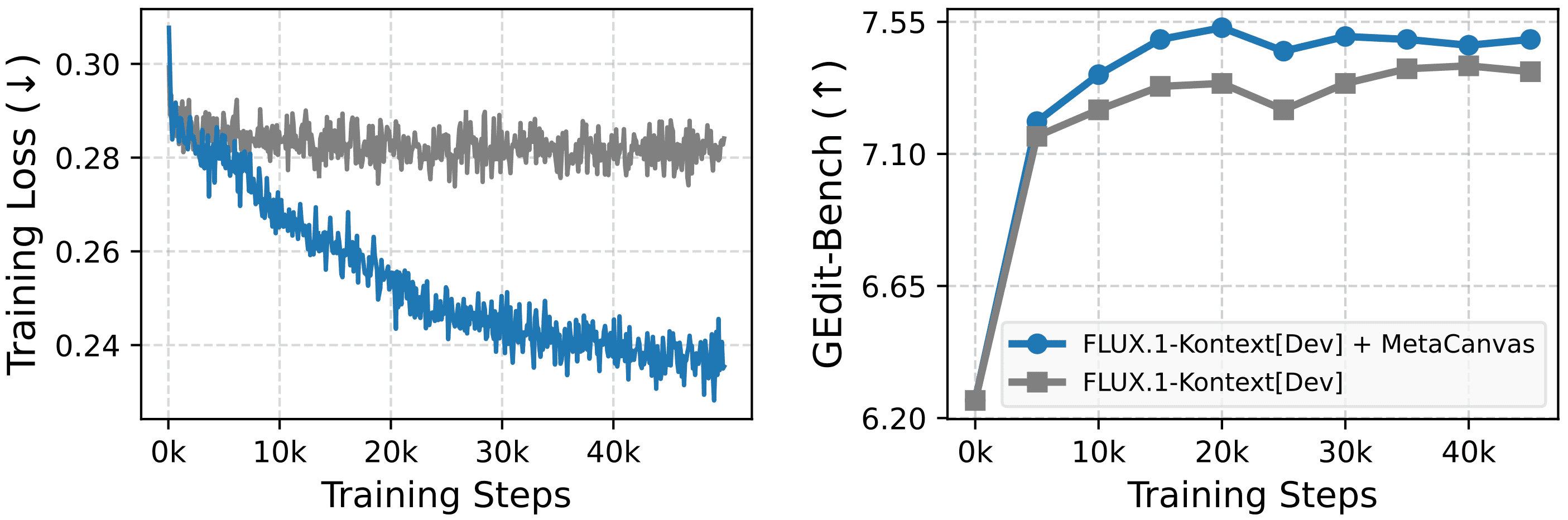
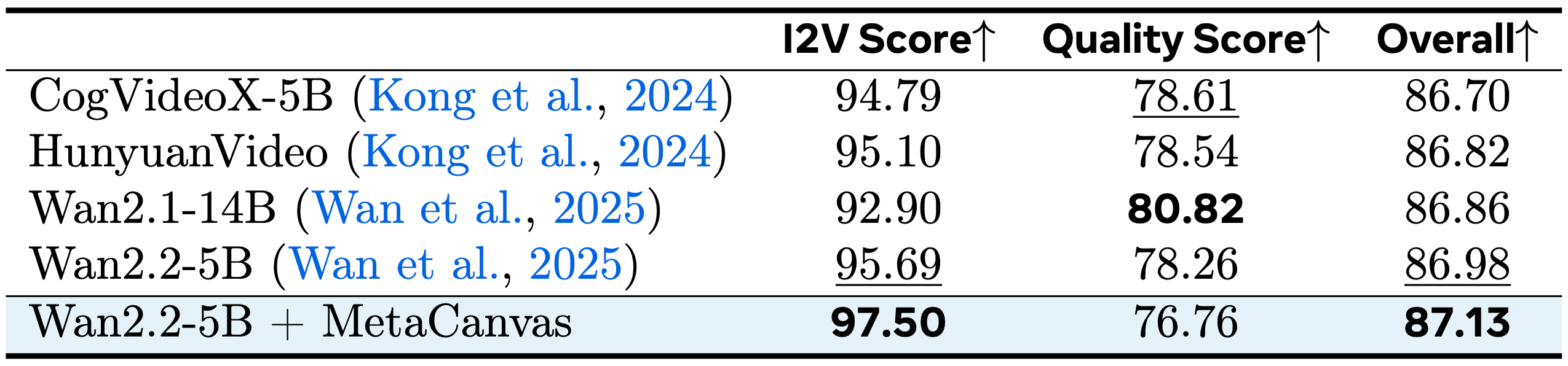
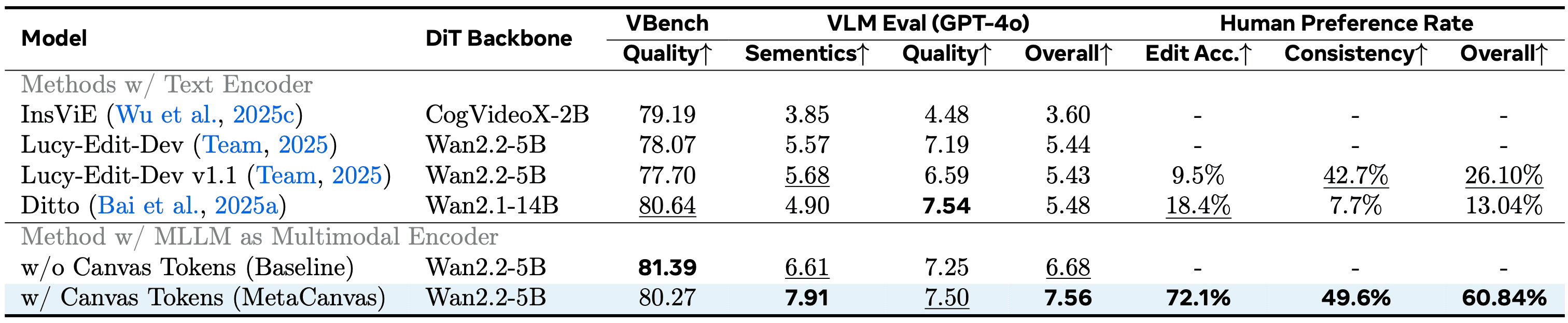
Figure 1: Overview of the MetaCanvas framework. MetaCanvas tokenizes the text and encodes it using the MLLM’s text embedder, while user-provided images and videos are encoded using both the MLLM’s visual encoder and the VAE encoder. The text embeddings produced by the MLLM are passed through a lightweight MLP connector and used as conditioning for the DiT. In addition, we append a set of learnable multidimensional canvas tokens to the MLLM input, which are processed using multimodal RoPE (Bai et al., 2025b). The resulting canvas embeddings are then fused with the noisy latents through a lightweight transformer-based connector with two blocks. Connector details are illustrated below. Green tokens represent media context tokens, blue tokens represent text context tokens, and purple tokens represent the canvas tokens.